Archive for the ‘Dataflow’ tag
Information-Centric Dataflow: Re-Imagining Reactive Distributed Computing
The Dataflow paradigm is a popular distributed computing abstraction that is leveraged by several popular data processing frameworks such as Apache Flink and Google Dataflow. Fundamentally, Dataflow is based on the concept of asynchronous messaging between computing nodes, where data controls program execution, i.e., computations are triggered by incoming data and associated conditions. This typically leads to very modular system architectures that enable re-use, re-composition, and parallel execution naturally. Most of the popular distributed processing frameworks today are implemented as overlays, i.e., they allow for instantiating computations and for inter-connecting them, for example by creating and maintaining communication channels between nodes such as system processes and microservices.
Connections and Overlays
The connection-based approach incurs several architectural problems and inefficiencies, for example: application logic is concerned with receiving and producing data as a result of computation processes but connections imply transport endpoint addresses that are typically not congruent. This typically implies a mapping or orchestration system. One key goal for Dataflow systems is to enable parallel execution, i.e., one computation is run in parallel, which also affects the communication relationships with upstream producers and downstream consumers. For example, when parallelizing a computation step, it typically implies that each instance is consuming a partition of the inputs instead of all the inputs. An indirection- and connection-based approach makes it harder to configure (and especially to dynamically re-configure) such dataflow graphs.
In some variants of Dataflow, for example stream processing, it can be attractive if one computation output can be consumed by multiple downstream functions. Connection-based overlays typically require duplicating the data for each such connection, incurring significant overheads. In large-scale scenarios, the computation functions may be distributed to multiple hosts that are inter-connected in a network. Orchestrators may have visibility into compute resource availability but typically have to treat the TCP/IP network as a blackbox. As a result, the actual data flow is locked into a set of overlay connections that do not necessarily follow optimal paths, i.e., the communication flows are incongruent with the logical data flows.
IceFlow: Information-Centric Dataflow
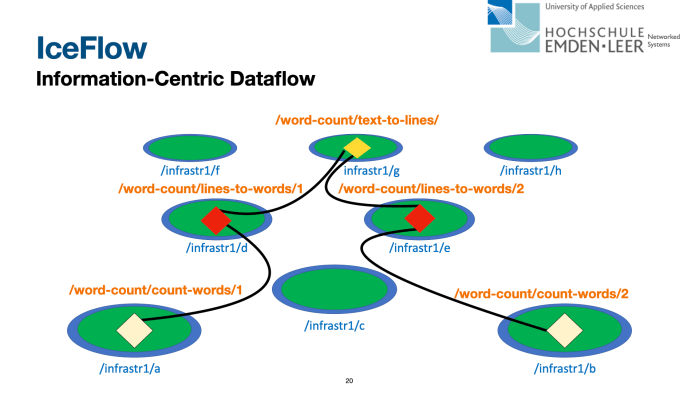
In our ACM ICN 2021 paper Vision: Information-Centric Dataflow – Re-Imagining Reactive Distributed Computing, we present IceFlow – an Information-Centric Dataflow system approach that supports traditional Dataflow with Information-Centric principles and that can be used as a drop-in replacement for existing Dataflow-based frameworks.
In addition to the paper, we also show a live of a joint optimization of computing and networking resources in IceFlow: Decentralized ICN-based dataflow system implementation.
IceFlow’s objectives are:
- reducing complexity in Dataflow systems by removing connection-based overlays and corresponding orchestration requirements;
- enabling efficient communication by reducing data duplication; and
- enabling additional improvements through more direct communication and caching in the network.

IceFlow is employing access to authenticated data in the network as per CCNx/NDN-based ICN for the communication between computation functions and provides additional features such as flowcontrol, partitions for data streaming, and a window concept for synchronizing computations in streaming pipelines. The contributions of this paper are:
- an ICN naming scheme for Dataflow;
- a concept for receiver-driven flow control in IceFlow-based Dataflow systems and for dealing with parallel processing in IceFlowbased Dataflow systems; and
- a prototype implementation.